
Sorting the Signal from the Noise
Five AI agent tools shipped in the last thirty days. I tried all of them. Here’s what I found.
The Simple One
There’s a technique called Ralph Loop. You write a prompt, set a completion condition, and start a loop. Each pass, Claude sees what it built last time — the files, the tests, the errors — and corrects itself. The loop keeps running until it’s done or you hit a limit.
I have it installed as a skill. I use it all the time. Kick off a task, walk away, come back to a clean commit history I didn’t supervise.
The results from the community:
- One person completed a $50k software contract for $297 in API costs
- A YC hackathon team generated six repos overnight
- Someone built an entire programming language over three months using nothing but the loop
It’s not sophisticated. It doesn’t need to be.
The Research One
Andrej Karpathy published Autoresearch on March 6th. About 630 lines of Python. A single script that autonomously designs, runs, and analyzes ML experiments.
He turned it loose. It ran 126 experiments on its own — about 12 per hour, roughly 100 overnight. Designed the hypotheses. Wrote the code. Ran the training. Analyzed the results. Decided what to try next. The repo hit 30,000 stars in its first week.
I haven’t tried it. The setup is complex enough that I haven’t gotten around to it. But the same pattern keeps showing up: give an AI a goal, let it iterate, walk away.
The Orchestrator
OpenAI released Symphony in early March. Where Ralph Loop is one agent in one loop, Symphony coordinates multiple agents working on different parts of the same problem.
It hooks into Linear — a Kanban-style task scheduler. You define your backlog, move a task to “ready,” and Symphony spins up an agent to work it. Pull request shows up when it’s done. In theory, you manage AI developers the same way you’d manage real ones: through tickets.
I set up a test repo, gave it simple tasks, and watched.
Some things got done — readmes, config files. But anything that required real thinking burned tokens at a rate that made me wince. A task I could hand Claude Code with a decent PRD was consuming way more resources through the pipeline.
I’m going to keep exploring it though. The use case I keep coming back to: one process finds issues and feeds them into the backlog. Another process picks them up, fixes them, commits them back. One creates the work. The other does the work. That virtuous cycle could be something real.
The Demo
Paperclip takes the orchestration idea to its logical conclusion: running an entire company with zero human employees. You define org charts, roles, budgets. AI agents execute autonomously.
Setup was painless. One command and you’re looking at this:
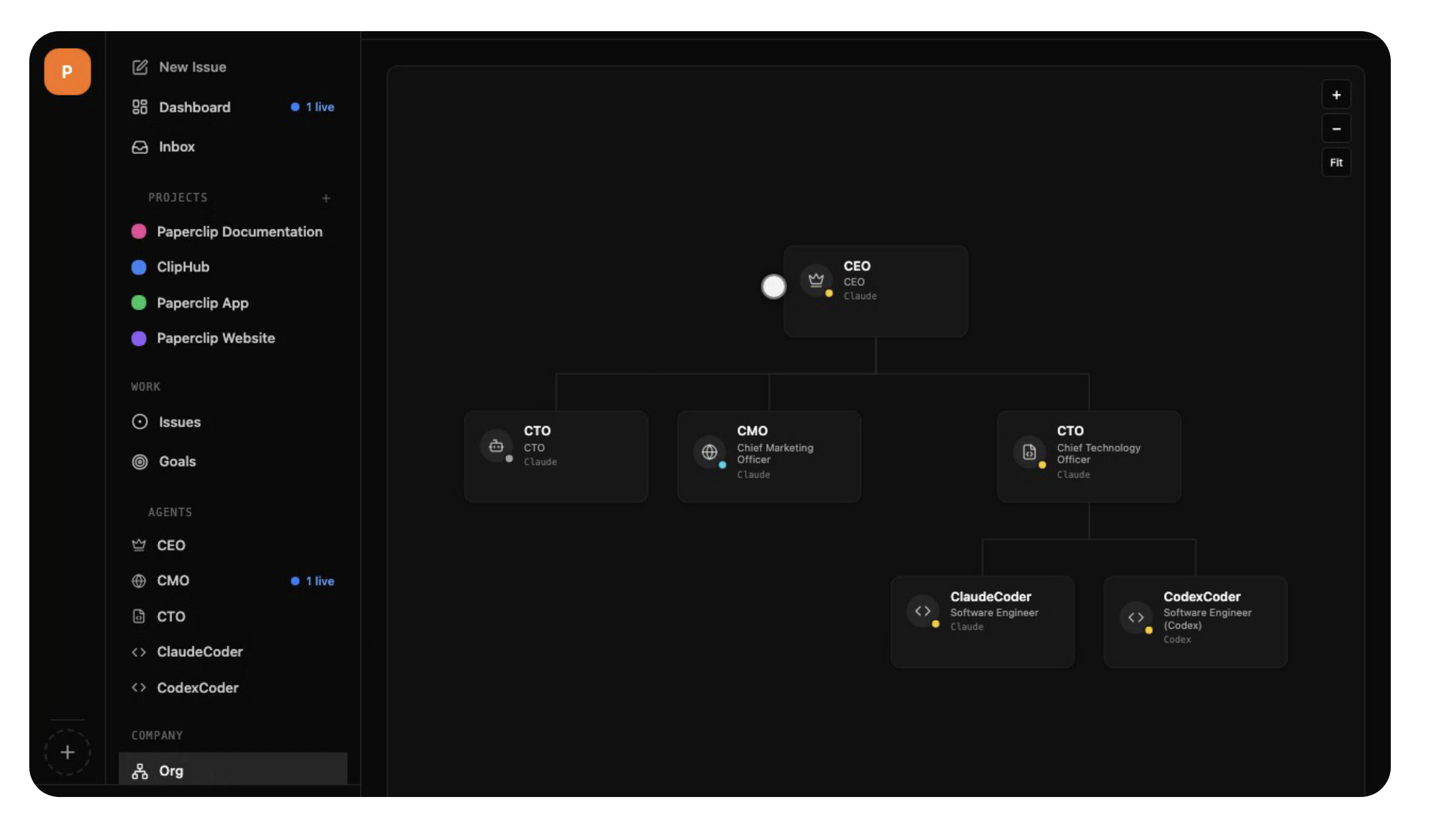
Beautiful dashboard. Projects. Agents with defined roles. The whole structure of a company laid out in front of you.
The problem is nothing happened. I hired a CEO and a CTO, gave them clear directions, and the system sat there. The CEO’s dashboard: “No assignments, no mentions, no approvals. Nothing actionable. Exiting heartbeat.”
The org chart was beautiful. The execution was not.
The Dangerous One
OpenClaw is an autonomous personal AI agent — email, calendar, web browsing, task execution. The idea is compelling. The security posture is not.
- CVSS 8.8 remote code execution vulnerability
- Authentication disabled by default
- ~40,000 exposed instances on the open internet
I don’t care how good the technology is if the front door is wide open.
The One That Actually Works
After all of that — the token burn, the idle CEO, the security holes — I want to talk about the one that blew my mind.
It’s called gstack. Garry Tan’s opinionated sprint process for Claude Code.
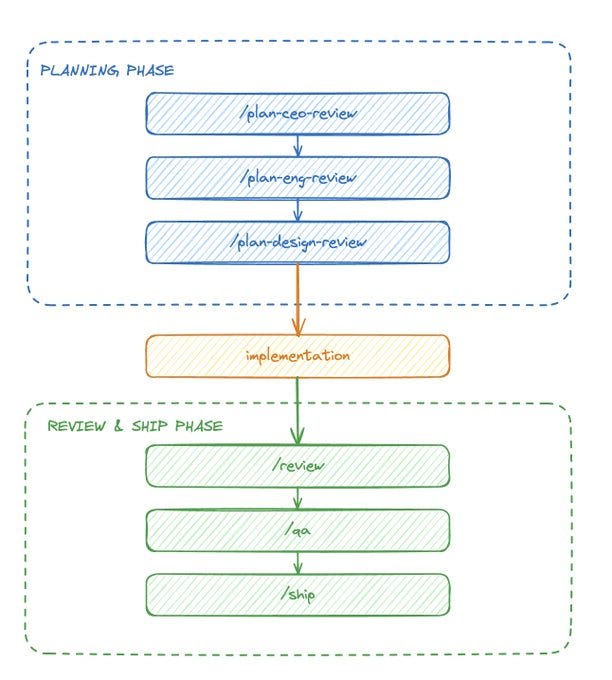
Think of it as a structured workflow: Plan, Build, Review, Test, Ship. Each phase has a command. Each command knows what it’s doing. I’ve been building a niche accounting product — replacing a decades-old desktop app with a modern SaaS platform. Dozens of format variations across jurisdictions, calculation engines, PDF pipelines. Real software.
I wrote a PRD, pointed gstack at it, and built the first three phases in a day. But the building wasn’t the part that got me.
It was the review.
What the review process catches
Standard review — not linting, not type checking. It reads what you built and finds real problems. My first pass caught:
- Three race conditions in the database layer
- A missing security check
- A strategy pattern that existed but was never wired into the registry
- N+1 queries that would have killed performance at scale
- Dead code
All auto-fixed.
Cross-model review — OpenAI’s Codex independently reviews the same diff. It caught a database migration Claude missed. Two models checking each other’s work.
Adversarial hardening — this one actively tries to break your code. It found TOCTOU race conditions, missing unique constraints, varchar limit violations, unsafe integer parsing, and gaps in multi-tenant isolation. Things you only catch by thinking about how someone would abuse the system, not just use it.
QA — opened a real browser, logged in, clicked through every page. Found two critical server component boundary errors that completely broke two tabs. Tests wouldn’t have caught them. A human might not have caught them for days.
Design consultation — researched competitors, browsed their actual websites, analyzed my existing patterns, and proposed a complete design system. Typography, color, components. Wrote it into a document every future command respects.
Over four days: 106 commits. 73 features. 10 review and adversarial fix rounds. Initial commit to v0.2.4. Roughly 78,000 lines across 212 files.
Every feature went through the same cycle. Build, review, adversarial hardening, QA. Every time, the review process caught things that would have shipped to production.
The punchline
And here’s the thing about gstack:
It’s just markdown files. No orchestration engine. No Elixir processes. No org charts. No dashboards. Just well-structured prompts that enforce a rigorous process.
The entire system that caught race conditions, ran adversarial security passes, and QA-tested my app in a real browser — it’s a collection of .md files telling Claude Code what to do and in what order.
For most people, I think this is the way to go. Not because it’s the most ambitious. Symphony and Paperclip are reaching for something bigger. But gstack works right now, today, on real projects. The process is the product — the firm back-and-forth between Claude and Codex, the mandatory review gates, the adversarial passes. That’s what ensures nothing slips through.
Agents writing code is the easy part. Agents writing code that’s safe to ship? That requires the loop.